Loading...

Loading...

Anyone who has shipped a Large Language Model (LLM) into production has felt this pain. You ask a clean question. You get a paragraph back when you wanted a number. You get a number wrapped in three sentences of preamble when you wanted a clean value. Extraction becomes a regex problem, and regex on free-form model output is a problem that never really ends.
Structured Outputs fix this at the source. Instead of parsing prose, you tell the model the exact shape you want, and you get that shape back. That shape is the contract every downstream step in your pipeline can rely on.
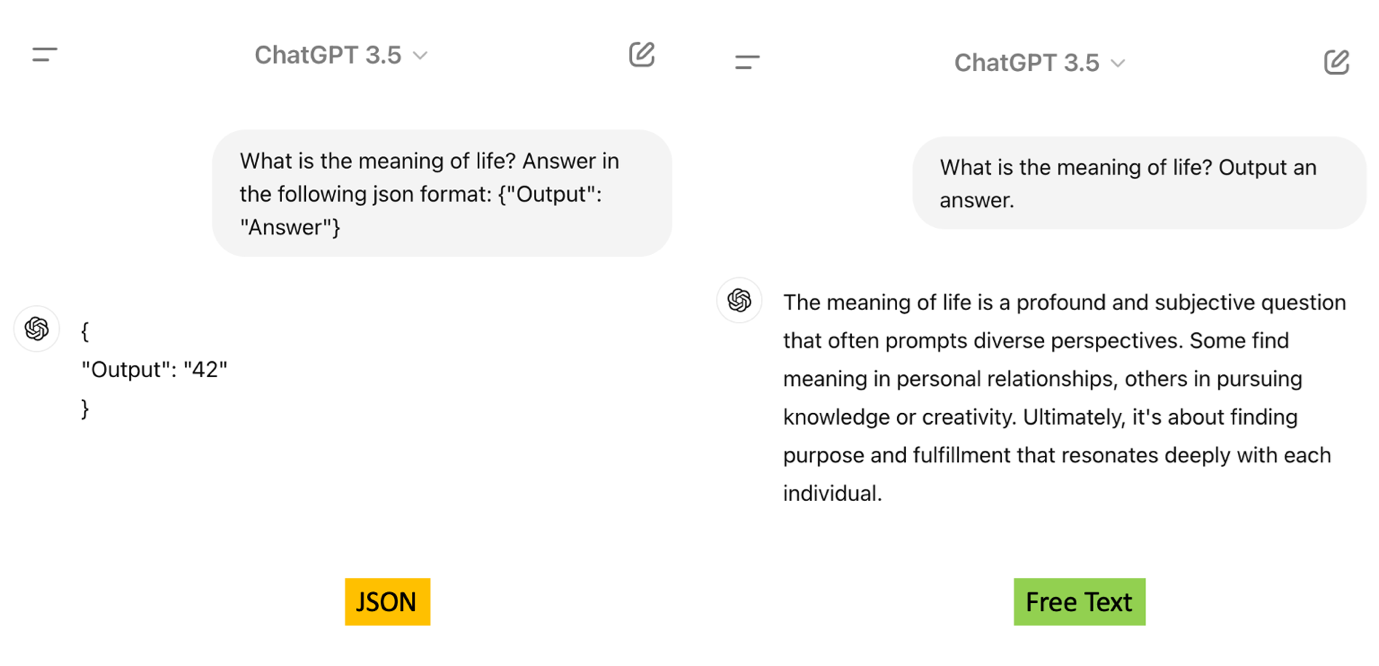 Figure 1 Comparison between JSON and free text output
Figure 1 Comparison between JSON and free text output
Here, we want the meaning of life in a short answer. Asking the LLM to output JSON gets exactly that (left): a number, 42, which pays homage to the Hitchhiker's Guide to the Galaxy. Without the JSON constraint (right), the answer meanders. Sometimes it is unparseable. Sometimes it drops the answer entirely inside a hedge. Either failure mode kills a pipeline.
When you chain LLMs together, every step feeds the next. Step one classifies an alert. Step two extracts entities. Step three drafts a response. If step one returns "This appears to be a phishing attempt, possibly related to credential harvesting," step two now has to decide what that means. JSON Outputs remove the guesswork. {"category": "phishing", "subtype": "credential_harvesting"} is unambiguous, machine-readable, and typed.
Three practical benefits show up right away:
To get JSON out of an LLM, one option is the Structured Outputs API by OpenAI. It works, but it uses a verbose JSON schema and only supports OpenAI models. If your stack spans providers (and most production stacks do), you need something portable.
At Simbian AI, we use StrictJSON. It defines a more concise StrictJSON schema and generates JSON reliably across major LLM providers (Meta, OpenAI, Google, Anthropic Claude) using an iterative prompting approach that guides the model into the right structure and type. GPT-4 and its successors work well here, but so do open-weights models we route to when latency or cost matters.
Compared to the JSON schema used by OpenAI and Pydantic, the StrictJSON schema runs at roughly 50% of the tokens. The savings grow the more fields the JSON contains.
 Figure 2 StrictJSON Schema is more concise than JSON Schema
Figure 2 StrictJSON Schema is more concise than JSON Schema
Concise schemas are not just a cost story. They are a quality story.
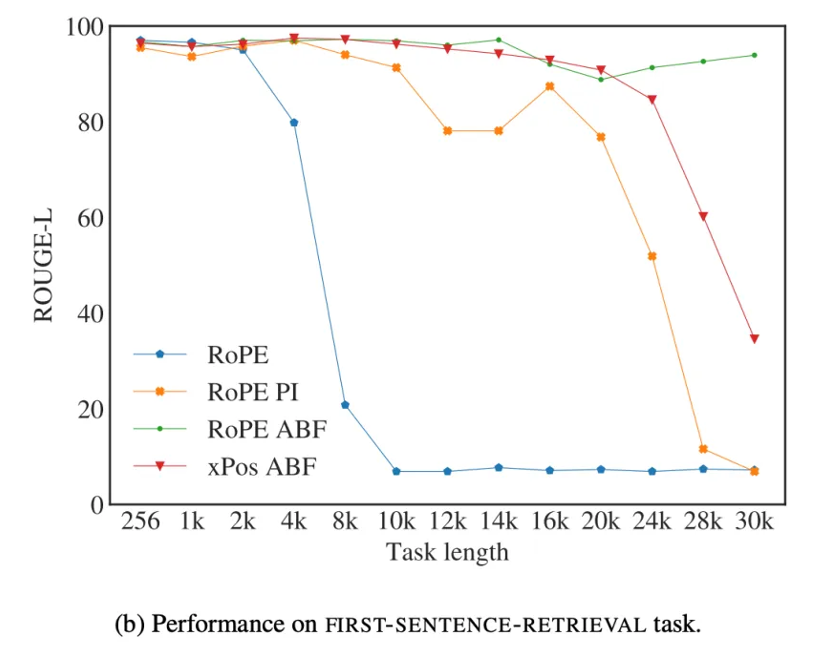 Figure 3 Longer context leads to poorer performance
Figure 3 Longer context leads to poorer performance
Image from Fig. 5b of Effective Long-Context Scaling of Foundation Models. 2023. Xiong et. al. https://arxiv.org/abs/2309.16039
Meta's long-context scaling paper shows the effect clearly: the longer the context (task length), the poorer the performance, measured by ROUGE-L against ground truth. Every token you spend on schema is a token the model cannot spend on the actual task. So the goal is fewer tokens in the context, both for cost and for accuracy.
This matters even more in security pipelines. When we chain an alert triage step into an investigation step into a response draft, each step inherits the context of the last. Bloat compounds. A verbose schema at step one becomes a slower, less accurate step four.
 Figure 4 Installing TaskGen
Figure 4 Installing TaskGen
Then define your own LLM.
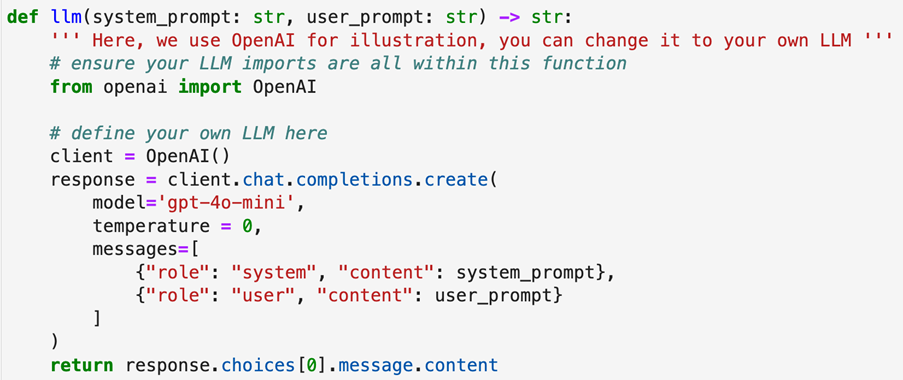 Figure 5 Defining your own LLM
Figure 5 Defining your own LLM
You are now ready to use StrictJSON:
 Using StrictJSON to extract entities
Using StrictJSON to extract entities
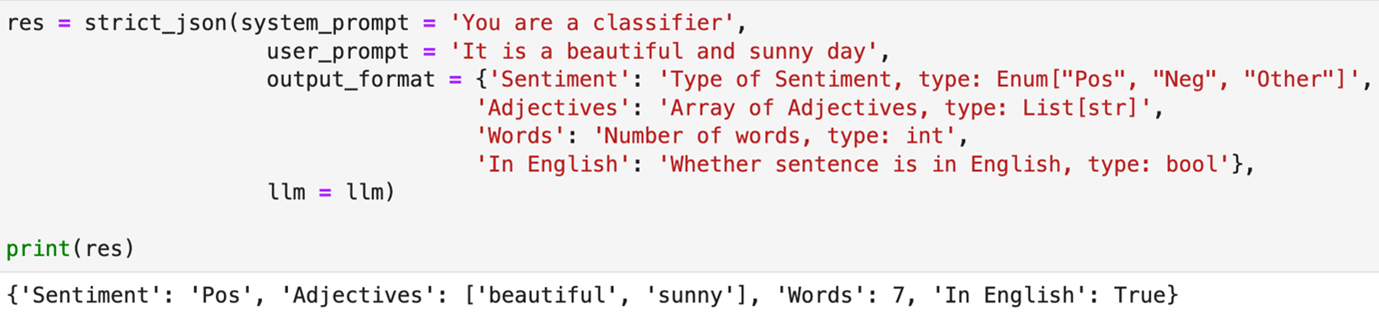 Figure 7 Using StrictJSON as a classifier
Figure 7 Using StrictJSON as a classifier
Write a system prompt with your instruction. Write a user prompt with your input. Define the output format with the key names, descriptions, and types you expect. StrictJSON will prompt the LLM to produce JSON in the exact format and type you specified.
StrictJSON currently supports the following data types: `int`, `float`, `str`, `dict`, `list`, `array`, `Dict[]`, `List[]`, `Array[]`, `Enum[]`, `bool`, `code`
 Figure 8 StrictJSON under the hood
Figure 8 StrictJSON under the hood
StrictJSON generates a system prompt that wraps each JSON field key with ### and each field value with <>. The LLM then emits the JSON keeping the ### key delimiters and filling in the <> value slots.
We parse the response by splitting on ###key###. That parser is deliberately forgiving: incomplete quotation marks or unmatched brackets do not break it, because the delimiter, not the JSON grammar, is what carries the structure.
If the JSON has any error (missing keys, missing values, wrong data type) StrictJSON generates an error message and passes it back to the LLM for regeneration. This retry loop is where reliability comes from. The LLM self-corrects, and the pipeline keeps moving. No manual intervention. No dropped requests.
Structured Outputs are not an academic exercise. Every non-trivial LLM application we run at Simbian is a chain, not a single call. Pipeline Chaining across specialised agents is how we get useful work out of models that are individually good but not individually complete.
A short list of places StrictJSON pays off in security work:
At each hop, the structured contract is what makes the chain deterministic. When a step fails, you know which field failed and why. When you want to swap out the underlying model (GPT-4 today, an open-weights alternative tomorrow), the schema stays the same and the downstream code does not care.
StrictJSON is used extensively in TaskGen (https://github.com/simbianai/taskgen) for Agent outputs. The original StrictJSON repository lives at https://github.com/tanchongmin/strictjson.
Check it out and use it in your pipelines. If you are running LLMs across more than one provider, the portability alone will save you a rewrite the first time you switch models.
Also, stay tuned for our next article, where we will share how to make LLM pipelines more robust using verifiers and ground-truth checking. Verifiers pair naturally with Structured Outputs: once the shape is guaranteed, the next question is whether the content in that shape is correct.


