Loading...

Loading...

The short answer: On Simbian's Cyber Defense Benchmark — 1,206 real attack-log investigations across 13 of 14 MITRE ATT&CK tactics — the strongest Claude on defense remains Opus 4.6 at 44.5% coverage. The newer Opus 4.7 (30.9%) and Opus 4.8 (32.7%) are tuned for faster, cheaper completion than for investigation depth. Sonnet 4.6 sits in between at 36.9%. Anthropic still owns the top four leaderboard slots, but no frontier LLM from any vendor clears the 50% threshold.
Anthropic released Opus 4.7 on April 16, 2026 as the first Claude with the Cyber Verification Program and production cybersecurity safeguards, followed by Opus 4.8. We ran every current Claude through the Cyber Defense Benchmark (arXiv 2604.19533) — a defense-oriented cybersecurity LLM gym with deterministic ground truth, covering 13 of 14 MITRE ATT&CK tactics and 105 procedures chained into real kill-chains. Which Claude should a SOC actually run today? Five months later, Opus 4.6 still holds the top spot.
▶ Watch the webinar — Why LLMs Fail in the SOC A 30-minute walkthrough of the Cyber Defense Benchmark: how every frontier model was scored, per-tactic breakdowns, and why no LLM clears 50% coverage on real attack logs.
Fourteen frontier models, 1,206 investigations, 100K+ events per environment. Every model reasoned through SQL queries against real Windows attack telemetry, chained across 105 MITRE ATT&CK procedures. The passing threshold is 50% coverage. The leader is Opus 4.6 at 44.5%, short of the bar but the only model to pass 7 of 13 tactics. The top four slots all belong to Anthropic:
| Rank | Model | Coverage | Median cost | Tactics passing |
|---|---|---|---|---|
| 1 | Opus 4.6 | 44.5% | $2.71 | 7 of 13 |
| 2 | Sonnet 4.6 | 36.9% | $2.21 | 2 of 13 |
| 3 | Opus 4.8 | 32.7% | $1.69 | 1 of 13 |
| 4 | Opus 4.7 | 30.9% | $1.65 | 0 of 13 |
Every other frontier model (GPT 5.5, Gemini 3.5 Flash, GPT 5, DeepSeek 4 Pro, Kimi 2.6) sits below 27%. The category isn't saturated. It's failing.
Opus 4.7 was the first Claude to ship with the Cyber Verification Program and automated detection of high-risk prompts — a meaningful safety posture for a frontier vendor. On the benchmark it lands at 30.9% coverage with 0 of 13 MITRE tactics passing. The mechanism is straightforward: 4.7 is tuned for fast, cheap completion. Its median investigation runs $1.65 in 243 seconds — the fastest and cheapest Claude on the leaderboard. Those are the right tradeoffs for coding and general agentic work, but on defense, coverage tracks how long the agent keeps pulling SQL against 100K+ events. The safeguards do what they were designed to do; they aren't a defensive-skill upgrade, and the benchmark doesn't measure safety posture.
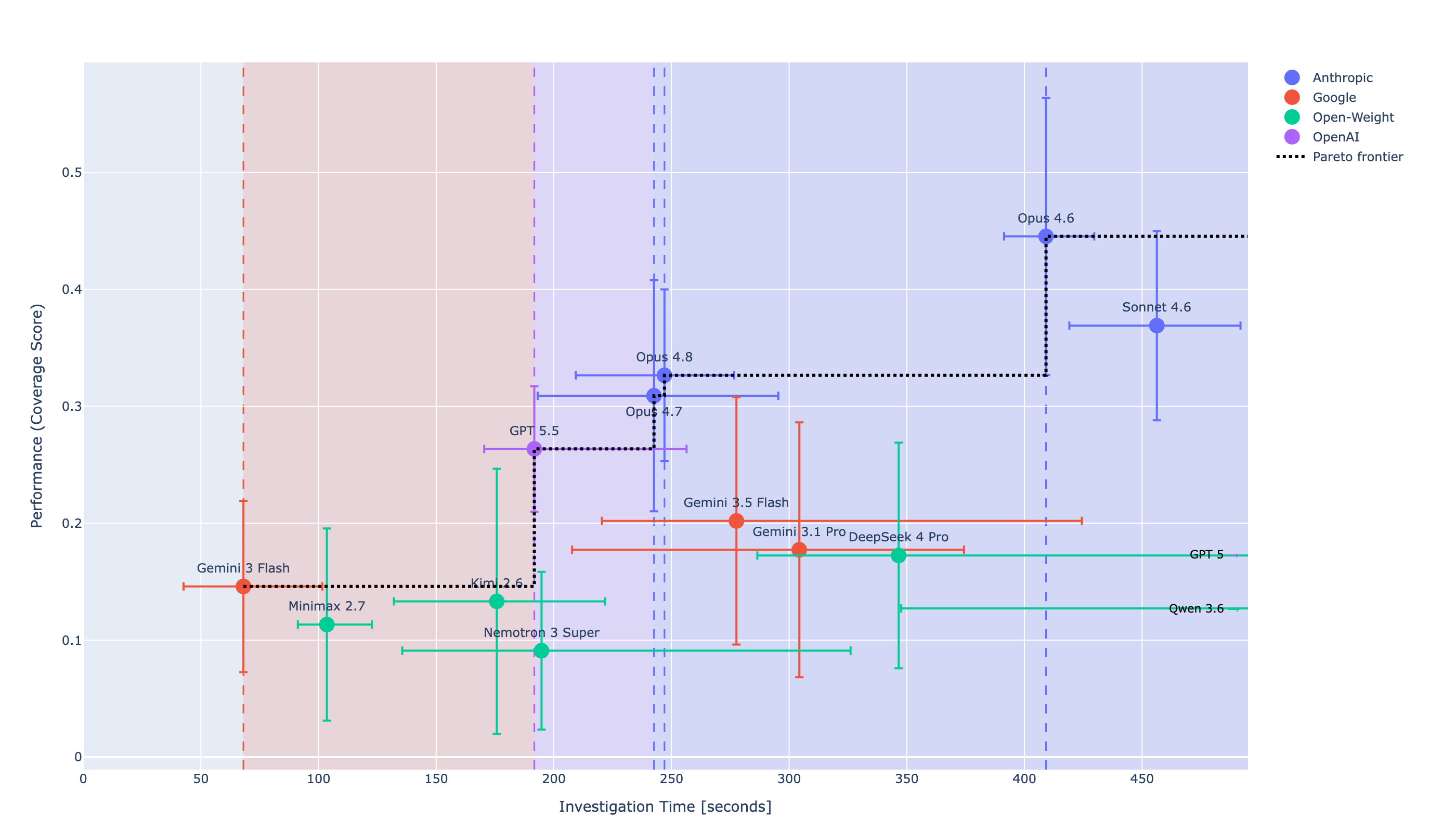
Opus 4.8 lifts coverage to 32.7% at $1.69 per investigation, with 1 of 13 MITRE tactics passing — roughly a two-point gain on 4.7 and the cheapest Claude on the leaderboard. The release character matches 4.7: optimized for fast, low-cost completion. On defensive work it still trails the five-month-older Opus 4.6 by 12 points of coverage. Across the 4.6 → 4.7 → 4.8 progression, headline benchmarks (coding, reasoning, agentic) have moved forward; defensive cybersecurity coverage on this benchmark has not. The most likely reason is the optimization target — investigation persistence isn't a metric recent post-training stacks are pointed at. We see the same trend across the other vendors, too, as compute resources are in high demand.
Sonnet 4.6 at $2.21 per investigation outscores both Opus 4.7 (30.9%) and Opus 4.8 (32.7%) by a clean margin. For a SOC choosing among Claudes today, the picture is:
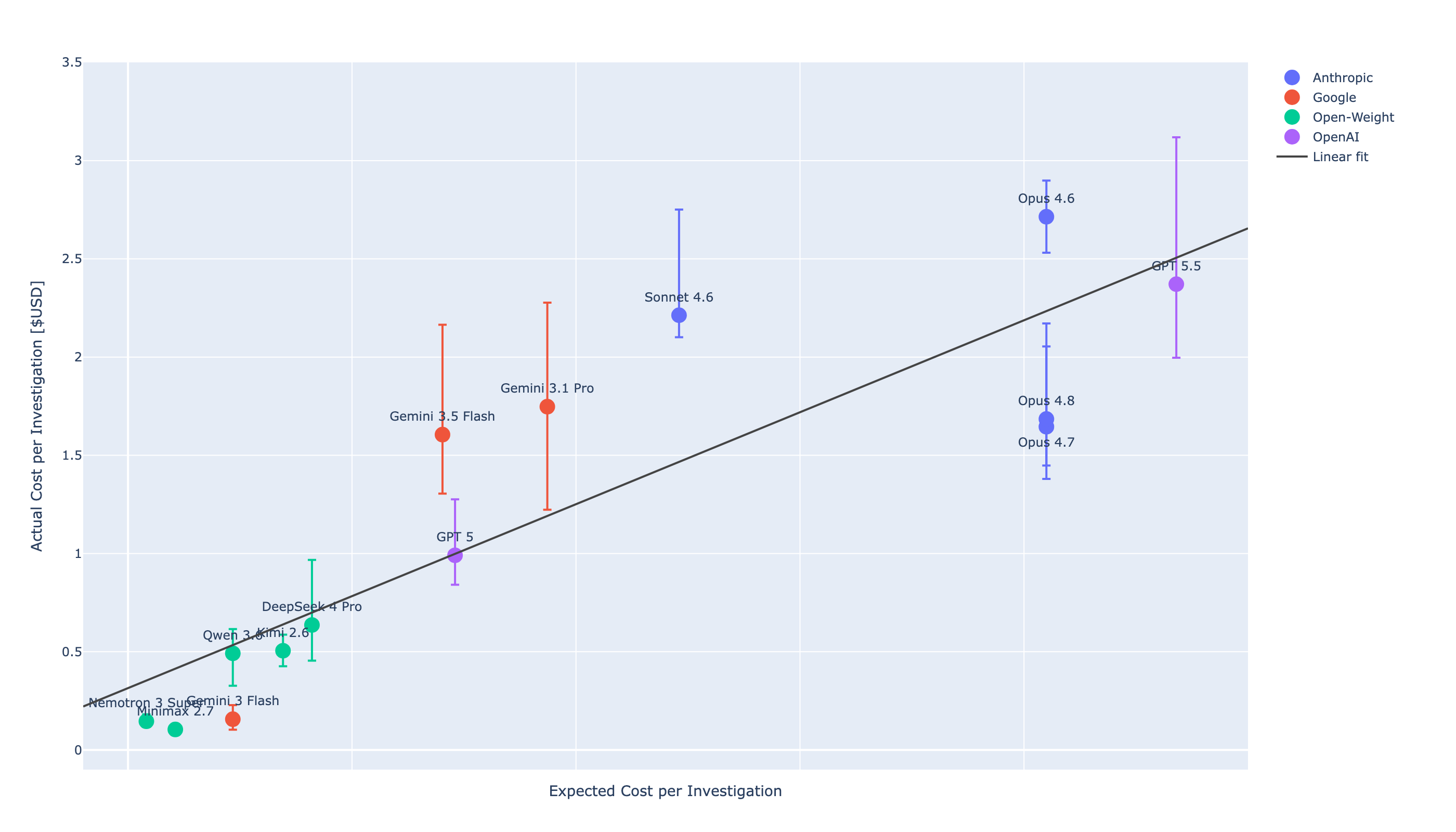
The skills that win on SWE-bench and coding benchmarks do not transfer cleanly to defense. SOC reasoning needs hypothesis generation under heavy noise, kill-chain comprehension and investigation planning, and iterative SQL across 100K+ events per environment — none of which appear on offensive or general-purpose cybersecurity LLM evals. Defensive work also penalizes speed: Gemini 3 Flash, fastest model at 68 seconds, scores 14.6%. Investigation depth tracks investigation time. This is the load-bearing finding: the harness, the context, and the skills around the model can address this shortcomings and matter more than the model itself. Simbian's 95% performance in production setting independently verified by a global MSSP cross-validate it. Forty-nine points come from the substrate, not the model.
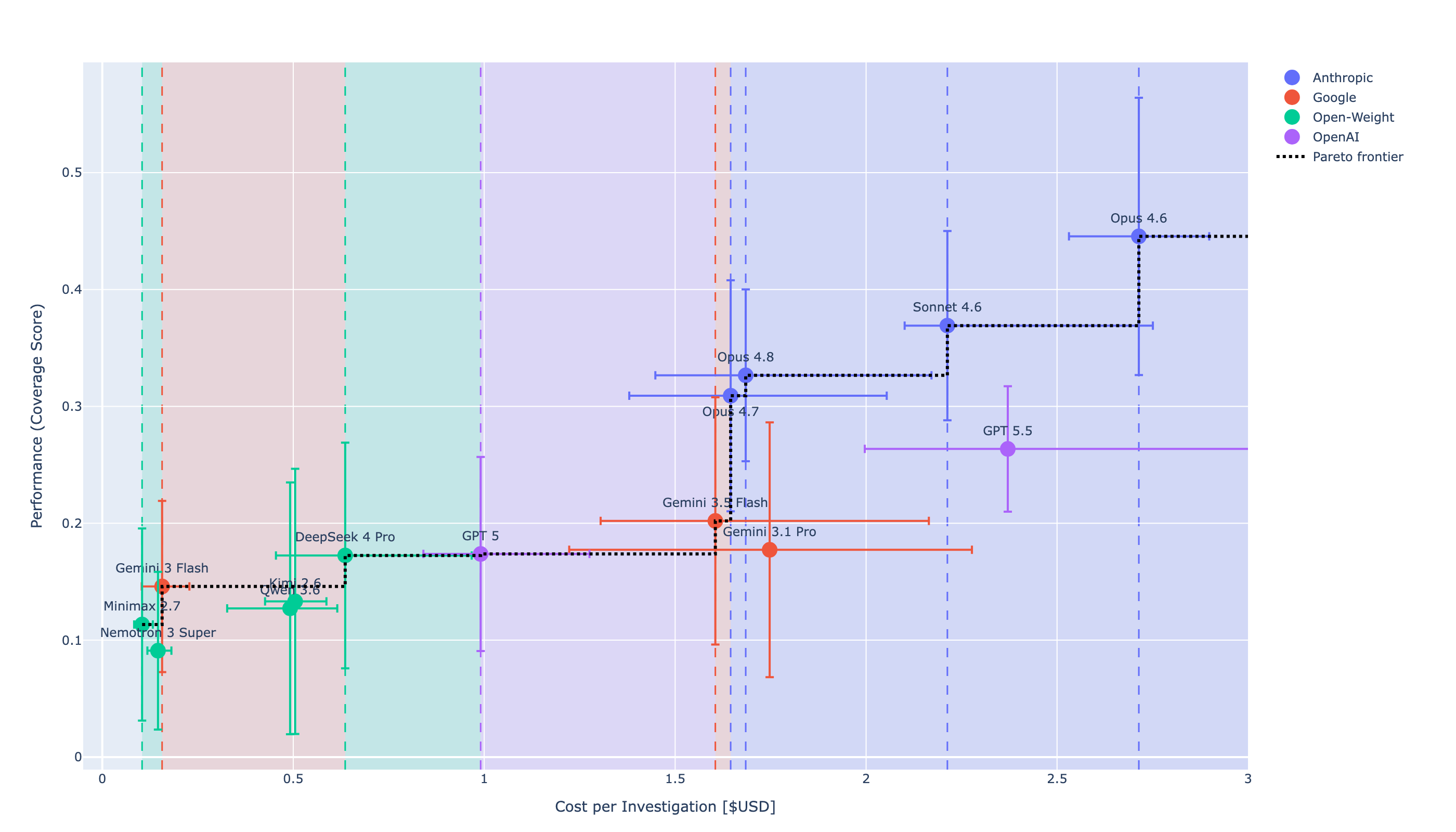
The practical message from the leaderboard is not "pick a different Claude." It is: do not put a raw LLM in front of your alert queue. Every Claude tops out below 50% coverage, and the gap is structural — not the next-release problem people keep betting on. For SOC work today, Opus 4.6 is the strongest Claude; Claude Opus 4.7 and 4.8 are tuned for different jobs. But more fundamentally: no raw frontier LLM, from any vendor, belongs as the SOC. The model is the easiest part of the system to swap. The hard parts — context, retrieval, the investigation loop — are what actually move the score.
Offense and defense are not symmetric problems.
A bigger context window does not fix this. A more capable reasoning chain does not fix this. These are things frontier models already do well, and it was not enough. SOAR cannot fix it either — rule-based playbooks break on the first novel alert and require an engineer to rewrite them. Copilots cannot fix it — they wait for an analyst to ask the right question, and attackers do not respect shift changes.
Simbian's AI SOC Agent runs on the same frontier LLMs that sit on the leaderboard above. The reasoning model is often a top-ranked Claude. What is different is the harness around it:
The result in production: 92% of alerts auto-resolved, 95% verdict accuracy, 100% alert coverage, 24×7×365 with no shift gaps. Same model. Same data. Forty-nine points of coverage from the harness, not the LLM.
| Approach | Coverage on defense | Fails on |
|---|---|---|
| Raw frontier LLM (best Claude) | 44.5% | unknown ground truth, agent gives up early |
| SOAR playbooks | ~25% automation | every novel alert, constant playbook maintenance |
| LLM copilots | analyst-paced | nights, weekends, anything an analyst forgot to ask |
| Simbian AI SOC Agent | 95% in production | — |
A model is a component. An agent is a product. If you are picking an LLM for your SOC, you are picking the wrong thing. Pick the harness.
→ Book a demo — see Simbian against your own telemetry
Which Claude model is best for cybersecurity? Claude Opus 4.6 is the strongest Claude on the Cyber Defense Benchmark at 44.5% coverage with 7 of 13 MITRE tactics passing. Sonnet 4.6 is the best price-performance pick at 36.9% coverage and $2.21 per investigation. The newer Opus 4.7 (30.9%) and Opus 4.8 (32.7%) trail 4.6 — they're optimized for faster, cheaper completion, which trades against investigation runway on defensive work.
Does Opus 4.8 close the cybersecurity gap? Not yet. Opus 4.8 scores 32.7% with 1 of 13 MITRE tactics passing — roughly two points above 4.7, and still 12 points below the older Opus 4.6. It is the cheapest Claude per investigation ($1.69) and the second-fastest. Headline benchmarks have moved release-over-release; defensive cybersecurity coverage on this benchmark hasn't. For SOC reasoning on raw LLMs today, Opus 4.6 remains the strongest Claude.
Can any LLM pass the Cyber Defense Benchmark today? No. Across 14 frontier models from Anthropic, OpenAI, Google, and open-weight providers, none crossed the 50% coverage threshold. The leader sits at 44.5%. By contrast, frontier LLMs routinely score above 80% on offensive-security benchmarks. Defense is the harder problem.
Is Claude the best LLM for SOC work? Yes, by a clear margin. Every Anthropic model on the leaderboard outscores GPT 5.5 (26.4%), GPT 5 (17.4%), and every Gemini and open-weight model. The top four leaderboard slots — Opus 4.6, Sonnet 4.6, Opus 4.8, Opus 4.7 — are all Claude. The best LLM for SOC today is Opus 4.6.
What closes the gap between LLM cybersecurity scores and a real SOC? The harness around the model. On the same benchmark, the best frontier LLM alone scored 46%; the same model wrapped in Simbian's harness scored 95% in production environments, as it is independently verified by a global MSSPs. The 49-point lift comes from context, skills, and the agent loop, not the underlying LLM.


