Loading...

Loading...

The industry is debating how fast AI finds bugs. We tested whether it can find attackers. None of the frontier models passed.
That is the headline result of the Cyber Defense Benchmark, released today by Simbian Research. Eleven frontier LLMs ran through 105 attack procedures in an agentic hunting loop against real attack telemetry. The best model — Claude Opus 4.6 — scored 63% on its strongest MITRE tactic and averaged 46%. Every model effectively missed entire attack categories. We summarize the results here, and the full report is available on our Cyber Defense Benchmark page.
Eleven frontier proprietary and open-weight models were evaluated across 26 campaigns, including models from Anthropic, OpenAI, Google, and leading open weight models by Alibaba, Minimax, DeepSeek, and Moonshot AI. A total of 884 runs ensured that each model was reliably measured. None scored a “pass” on the leaderboard.
Rank | Model | MITRE Tactic Performance | Flags % | ||
Average | Best | Worst | |||
1 | Opus 4.6 | 46% | 63% (Resource Dev.) | 25% (Collection) | 4.5% |
2 | Sonnet 4.6 | 35% | 50% (Resource Dev.) | 16% (Collection) | 3.4% |
3 | Opus 4.7 | 28% | 46% (Resource Dev.) | 4% (Collection) | 3.0% |
4 | Gemini 3.1 Pro | 18% | 29% (Resource Dev.) | 5% (Exfiltration) | 2.0% |
5 | GPT 5 | 17% | 38% (Impact) | 2% (Initial Access) | 2.2% |
6 | Gemini 3 Flash | 15% | 24% (Resource Dev.) | 4% (Exfiltration) | 1.4% |
7 | Kimi 2.6 | 13% | 21% (Resource Dev.) | 2% (Exfiltration) | 1.1% |
8 | Qwen 3.6 | 13% | 22% (Resource Dev.) | 3% (Exfiltration) | 1.6% |
9 | Minimax 2.7 | 11% | 19% (Persistence) | 2% (Exfiltration) | 1.0% |
10 | Kimi 2.5 | 9% | 15% (Resource Dev.) | 2% (Exfiltration) | 0.9% |
11 | DeepSeek 3.2 | 9% | 16% (Resource Dev.) | 1% (Exfiltration) | 0.8% |
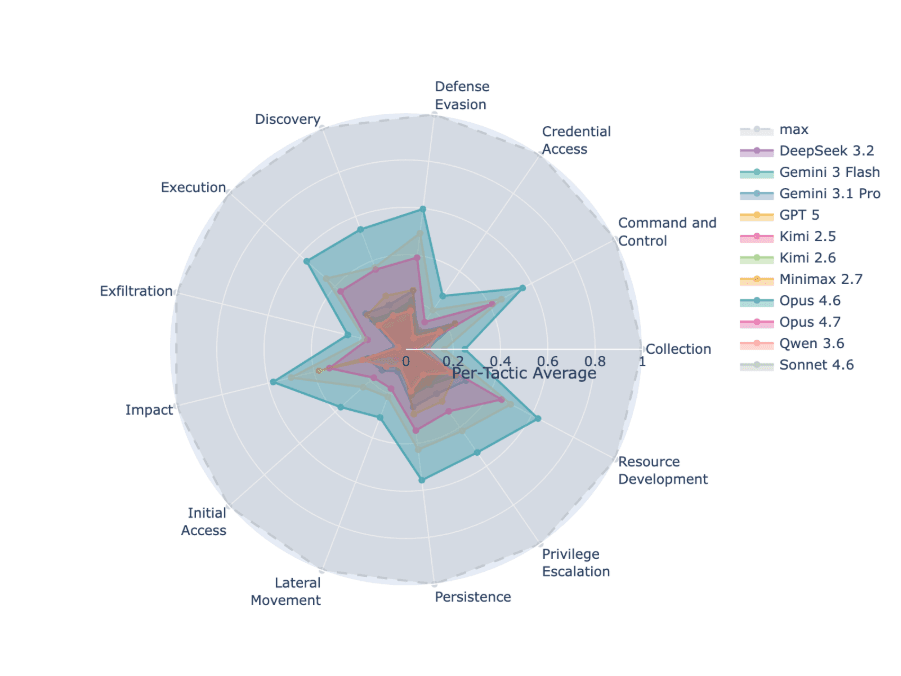
Opus 4.6 is the clear leader, with 1.32x more flags than the next-best model. But 4.5% flags out of thousands of malicious events per run is still a fraction of the total. The radar chart of MITRE tactic coverage tells the rest of the story: Opus 4.6 shows substantive coverage across 8 out of 13 probed Tactics (Command and Control, Defense Evasion, Discovery, Execution, Impact, Persistence, Privilege Escalation, Resource Development). Sonnet 4.6 achieved one > 50% score (Resource Development). Every other model collapses toward the center. Partial visibility means the attacker's later stages go unnoticed – which in practice is indistinguishable from no visibility at all.
One detail the leaderboard does not show: several models stopped making progress well before exhausting their query budget as they thought they had “completed” the campaign. An agent that gives up is not a defender – it is a demo.
The benchmark also found that detection ability and cost of investigation are not linearly related. Gemini 3 Flash costs $0.19 per run and finds 1.4% flags. Opus 4.6 costs $17.98, roughly 100x more, and finds 4.5% flags, which is about 3x more. That is the Pareto frontier in one sentence: the curve bends sharply, not smoothly. The cost-quality trade-off is a cliff, not a slope.
Rank | Model | Average Cost per AI Investigation |
1 | Opus 4.6 | $17.98 |
2 | Sonnet 4.6 | $12.99 |
3 | Opus 4.7 | $8.72 |
4 | Gemini 3.1 Pro | $1.85 |
5 | GPT 5 | $1.07 |
6 | Gemini 3 Flash | $0.19 |
7 | Kimi 2.6 | $0.52 |
8 | Qwen 3.6 | $0.54 |
9 | Minimax 2.7 | $0.11 |
10 | Kimi 2.5 | $1.44 |
11 | DeepSeek 3.2 | $0.91 |
GPT-5 and Gemini 3.1 Pro sit in the mid-price range at $1.07 and $1.85 per run. Both plateau around 2% flags and stop climbing. Throwing more budget at them does not help, because the limit is not token cost, it is that the agent believes it has completed its task and has no work left to do.
For practitioners evaluating models for production SOC use, this has two practical implications. First, you cannot assume a model that is two-thirds of the price gets you two-thirds of the detection – the curve does not work that way. Second, if you are buying on cost alone, you are buying an agent that gives up.
Frontier models are rapidly getting more and more capable at finding and exploiting software vulnerabilities. So why does the same model class fail when you ask it to defend? The asymmetry is structural, not a matter of training data. Offense has a clear goal and a fast feedback loop. Did the exploit land? Did the shell open? Did I get root? The model knows when it has won. Every iteration refines toward that signal, and the environment cooperates – errors surface immediately, successful paths compound.
Defense has none of that. The goal is to "find every malicious event in this telemetry" as this is the only way to understand the scale of an attack and stop the attacker. The challenge is you have no idea how many there are – the ground truth is invisible. Signal-to-noise collapses because normal enterprise activity looks a lot like reconnaissance until you have context. Every wrong hypothesis costs you queries without telling you that you were wrong. You cannot know when you have won, only when you have run out of budget.
Scale does not fix this. A bigger context window does not fix this. A more capable reasoning chain does not fix this. These are all things frontier models already do well, and it was not enough.
Ask a frontier LLM what MITRE ATT&CK technique maps to LSASS memory dumping, and it will answer correctly. Ask it to look at ten thousand Sysmon events and tell you whether anyone is dumping LSASS right now, and the answer is very different.
This is the gap in prior cybersecurity benchmarks. CTI-Bench uses multiple choice. CyBench runs CTF puzzles in a Kali container. CyberSOCEval asks MCQ questions about sandbox malware reports. CTI-REALM is agentic but measures whether a model can convert a threat report into a Sigma rule, not whether it can find an attacker in logs it has never seen. Most of these are gameable by training on the test set.
The Cyber Defense Benchmark was built to be difficult to game. It replays real Windows telemetry — Sysmon and Security event logs — captured from controlled lab environments running various attack vectors including Empire, Covenant, Mimikatz, and Rubeus. Each campaign run mutates with seeded randomization hostnames, IP addresses, user identities, domain SIDs, timestamps, and other log fields that could be used to connect pieces of an attack into a coherent attack picture. No two runs present identical data. The model receives a threat intelligence briefing and a SQL-queryable log database, then gets 50 queries to find the attacker. Scoring is deterministic: exact timestamp matches against ground truth. No LLM judges, no subjective rubrics.
Here is the finding buried under the failure: the gap between 46% average per-tactic performance and 95% verdict disposition accuracy in production is closeable. At Simbian we know because we have closed it.
Simbian's AI SOC Agent achieve 95% accuracy in production enterprise environments for SecOps cyber defense. The model doing the reasoning is often the same as one of the models on the leaderboard above. What is different is what surrounds it.
In SecOps, the scaffolding around the model, what we call the harness, is the key to better security. Context about the organization's assets, users, baseline behavior, and previous incidents. Deterministic retrieval that grounds every hypothesis in real data. Agentic loops structured around investigation patterns that analysts actually use, not ReAct-for-its-own-sake. Tool access calibrated to what the agent needs at each step. An assessment loop that ensures the LLM keeps generating and evaluating hypotheses until the task is complete. Cost controls so the agent can afford to hunt the way a good hunter actually hunts. Simbian’s AI solutions provide this scaffolding.
This is why the benchmark results should not be read as "AI cannot do defense." They should be read as "an LLM alone is not a defender, and that distinction matters commercially." A model is a component. An agent is a product. An AI-powered and AI-ready SOC need both.
If you are evaluating AI for security operations, three things follow from the benchmark:
Do not rely on just an LLM. Buy an agent with a harness. The raw model is the easiest part to swap out. The context, retrieval, tool integration, and investigation patterns are the hard parts — and the parts that determine whether you get 46% coverage or 95% accuracy.
Test on your own telemetry, not on a vendor's demo environment. Context morphing exists in this benchmark for a reason: a model that performs well on scrubbed, curated data can collapse on real noisy logs. If a vendor will not run their agent against your data before you buy, ask why.
Ignore knowledge-recall benchmarks when evaluating detection capability. The fact that a model can correctly answer "what technique is T1003.001?" tells you nothing about whether it will find T1003.001 happening in your logs. Those are different tasks. Past benchmarks measured the first. The Cyber Defense Benchmark measures the second. That is why the results look different.
If you want the practical version of this argument, you can book a demo with Simbian and put it against your own telemetry.
AI-armed attacks will continue to redefine the threat landscape. Now we need to extend AI models so that they are equally effective at defending our organizations. This benchmark is one step in helping us understand how to do that.
Q: What is the Cyber Defense Benchmark? A: It is the first scalable AI security benchmark that places an agent in front of real attack telemetry and asks it to autonomously hunt. Eleven frontier LLMs were tested across 884 runs covering 105 attack procedures and 93 MITRE ATT&CK sub-techniques. Agents receive a threat briefing plus a SQL-queryable log database and submit exact timestamps of malicious events. Scoring is deterministic, with no LLM judges.
Q: Why did every frontier LLM fail? A: Defense is structurally harder for an LLM than offense. Offense has a clear goal and fast feedback – did the exploit work? Defense has unknown ground truth, thousands of malicious events hidden inside far more noise, and no signal that you have found everything. Raw reasoning capability is not enough without a harness that grounds the agent in organizational context and guides investigation.
Q: Can a cheaper model work for production SOC use? A: Not on its own. The cost-quality relationship is a cliff. Gemini 3 Pro at $1.85 per run finds 2% flags; Opus 4.6 at $17.89 finds 4.5%. Mid-priced models plateau around 2% flags because the model thinks it has completed its work and requires no additional queries. In production, cheaper models only work inside a harness that compensates for their reasoning limits.
Q: Is the benchmark Windows-only? A: For v1.0, yes. All procedures are sourced from Windows endpoints using Sysmon and Security event logs. Linux, macOS, cloud, and network telemetry are planned for future versions. The current library covers 93 ATT&CK sub-techniques across 13 of 14 tactics. The known gap is Reconnaissance, which v1.0 does not yet include, and is planned to be created using Simbian PenTest agent.
Q: Will future frontier models crack this benchmark? A: Some ground will be made up as every frontier release is more capable than the last. But the structural asymmetry between offense and defense does not disappear with more parameters. The path to 95% accuracy in production will continue running through better harnesses, not through raw LLM progress alone. The benchmark will keep raising the ceiling as models improve.
Q: Where can I see the full results? A: The full leaderboard, methodology, per-procedure detection rates, and Pareto frontier analysis are published on the Cyber Defense Benchmark page. Additional models and runs are being added.
Every frontier model on the current leaderboard is going to get better. The benchmark will get harder. The practical question for SOC leaders is not which model wins next quarter — it is whether the agent you deploy today has the harness to get from 46% to 95%. On April 29, we are walking through the full results and the techniques that close that gap in a session called "Claude and OpenAI Will Change Security — Just Not the Way You Think." Seats are limited.


