Loading...

Loading...

The best LLM for cybersecurity isn't the one with the highest general benchmark score. It's the one that addresses your SOC specific needs best. The one that finds the most attack evidence at a cost and speed your SOC can sustain. We tested 12 models end-to-end on 26 diverse real Windows attack campaigns to answer that question with data, not spec sheets.
Each model ran autonomously inside a ReAct harness with access to a SQL log database. This setup is provider-agnostic and thus objective. We have a proprietary harness too and plan to study Claude Code, Codex, and other commercial harnesses in a follow-up, but this time we benchmark LLMs. The 12 models span four provider groups:
Three numbers matter: performance, cost, and investigation time. Full methodology is in the Cyber Defense Benchmark paper.
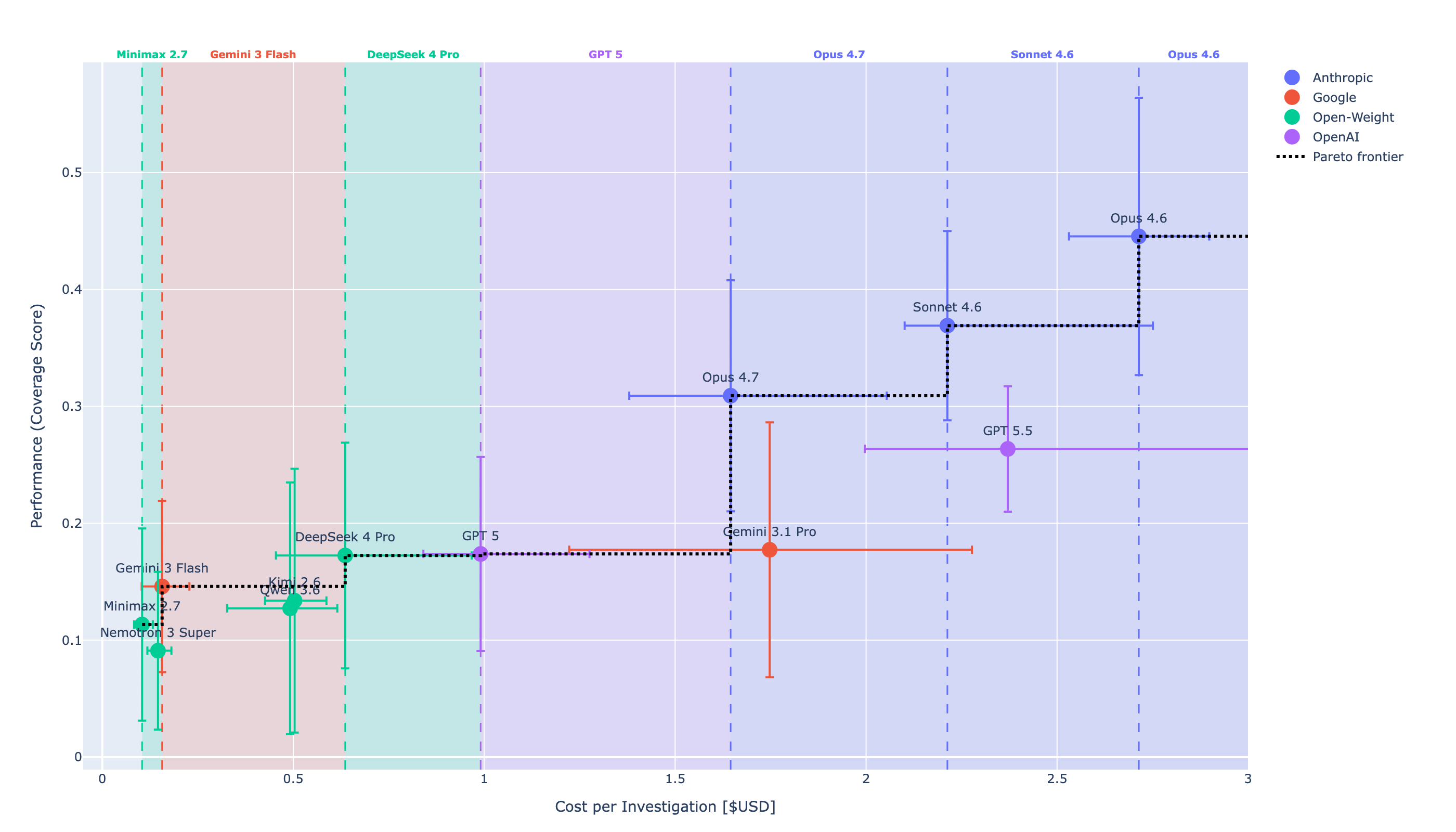
Performance is measured using the Coverage Score: the fraction of malicious logs each model both finds and submits across every step of the attack procedure, averaged over 13 of 14 MITRE ATT&CK tactics and normalised to 1. Cost is the cache-adjusted dollar amount per investigation. Not all providers enable prompt caching by default. Without it, you reprocess the entire history on every turn. Exponential growth you can't unwind.
The Pareto frontier:
| Model | Performance | Cost |
|---|---|---|
| Opus 4.6 | 0.45 | $2.71 |
| Sonnet 4.6 | 0.37 | $2.21 |
| Opus 4.7 | 0.31 | $1.65 |
| GPT 5.5 | 0.26 | $2.37 |
Opus 4.7 is the cheapest flagship that still scores ~30% across tactics. Opus 4.6 holds the performance ceiling (45%) at a 64% cost premium. GPT 5.5 is dominated on this chart: roughly the same cost as Sonnet 4.6 with materially worse coverage.
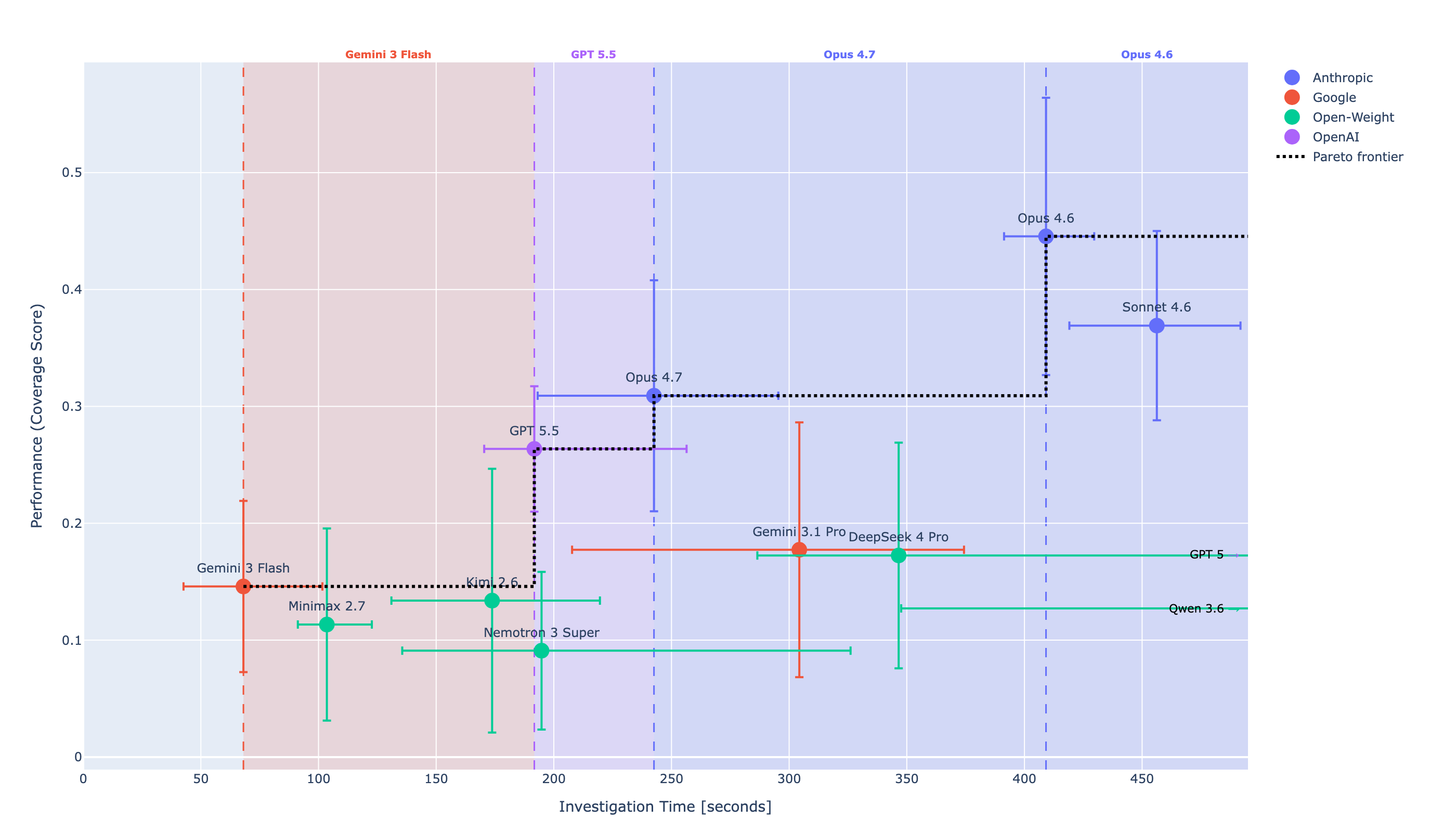
Investigation time is the median wall-clock seconds spent on SQL querying and analysis turns (submit and retry overhead stripped so providers aren't penalised for infra throttling). On speed, the ranking flips: GPT 5.5 (~200s) > Opus 4.7 (~250s) > Opus 4.6 (~400s) > Sonnet 4.6 (~450s).
Speed is dominated by decoding rate × number of turns plus thinking budget:
| Model | Inference Speed |
|---|---|
| GPT 5.5 | ~90 tok/s |
| Opus 4.6 / 4.7, Sonnet 4.6 | ~60 tok/s |
OpenAI decodes roughly 1.5× faster than Anthropic at the same tier. But Opus 4.7 completes investigations in ~30 SQL turns versus Sonnet/Opus 4.6's ~50. Fewer turns is a bigger lever than per-turn speed.
Too many factors trade off against each other, and they cancel in ways you wouldn't predict from a spec sheet:
LIMIT and projected columns vs broad SELECT * over an event table. Pulling random data blows up the context window and affects cost, speed, and performance.reasoning_tokens separately from completion_tokens; some providers bake thinking into completion silently. That directly affects your ability to decompose costs after the fact.The AI SOC LLM Leaderboard tracks how these trade-offs shift as new models release.
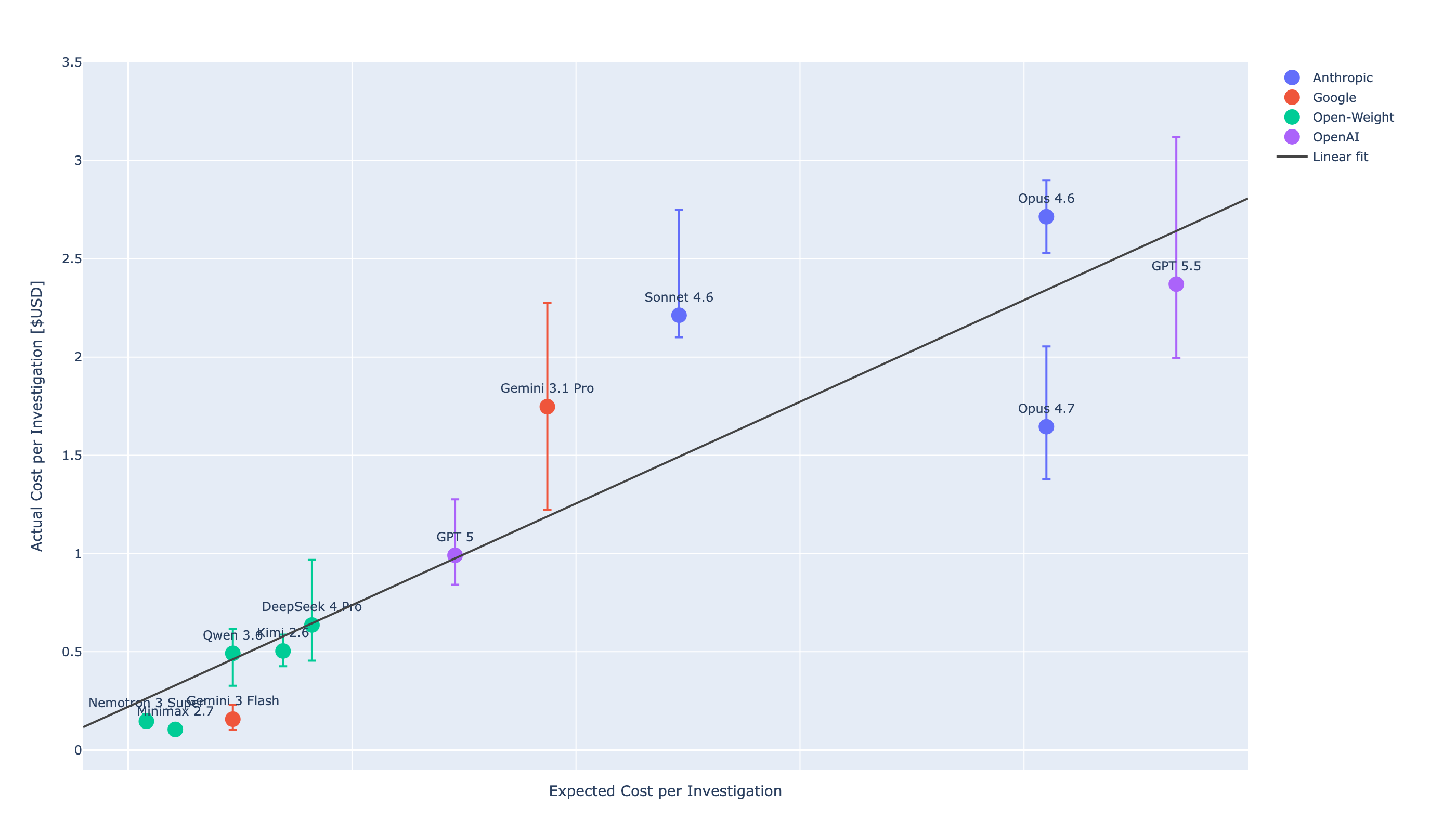
Expected cost (linear fit from per-token pricing) vs actual cost (cache-adjusted) gives R² ≈ 0.83. About 80% of cross-model cost variance is explained by per-million-token list prices alone. The residuals are interesting: Opus 4.7 sits below the line (cheaper than predicted), Sonnet 4.6 sits above (more turns per investigation, not deeper thinking per turn).
If you don't have time or budget to benchmark, $/Mtok is a reasonable first-cut cost screen. It's not a substitute for measuring performance or speed. Our Cyber Defense Benchmark costs ~$1.8K USD. That's the price of knowing rather than guessing.
$/Mtok. Good ~80%, fails on the flagship tier.Newer flagships are optimising for cost, not performance. Opus 4.7 is cheaper and faster than Opus 4.6, and lower performance. GPT 5.5 is faster but more expensive than 4.7, with lower coverage than either Opus.
If you're buying a security product, ask the vendor what model they're using today, what they were using six months ago, and whether they re-benchmark when the underlying model changes. The harness, the context architecture, and the engineering around the model matter as much as the model itself. For a deeper look at how LLM selection plays out in practice, watch Claude & OpenAI Will Change Security — Just Not the Way You Think. For a broader view of what's reshaping security operations, Security for Winners covers the strategic decisions security leaders are navigating right now.


